This page provides an overview of the extraction framework which is used by the Web Data Commons project to extract Microdata, Microformats and RDFa data, Web graphs, and HTML tables from the web crawls provided by the Common Crawl Foundation. The framework provides an easy to use basis for the distributed processing of large web crawls using Amazon EC2 cloud services. The framework is published under the terms of the Apache license and can be simply customized to perform different data extraction tasks. This documentation describes how the extraction framework is setup and how you can customize it by implementing your own extractors.
Contents
1. General Information
The framework was developed by the WDC project to process a large number of files from the
Common Crawl in parallel using the cloud services of Amazon. The extraction framework was originally designed by Hannes Mühleisen for the
extraction of Microdata, Microformats and RDFa from the 2012 Common Crawl
corpus. Later, it was extended to be able to extract hyperlink graphs as
well as the web tables. The software is written in Java using Maven as the build tool and can be run on any operating system. The current version (described in the following) allows
straightforward customization for various purposes.
The picture below explains the principle process flow of the framework, which is basically steered by one master node, which can be either a local server or machine, or a cloud instance itself.
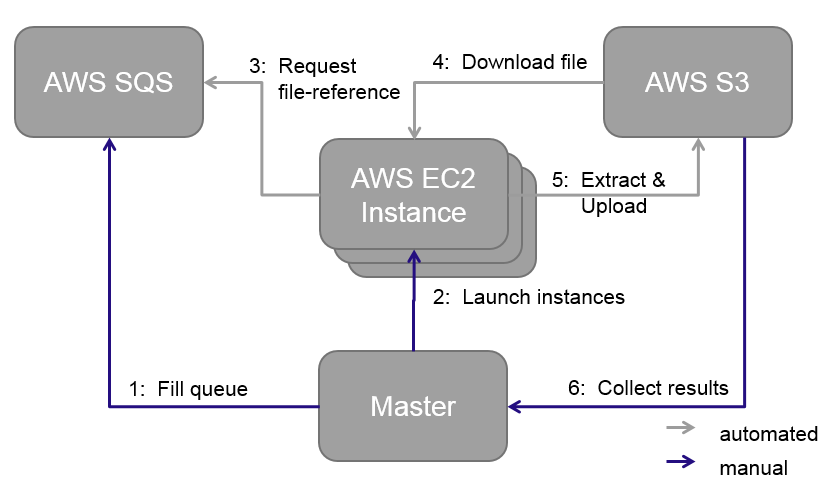
- From the master node the AWS Simple Queue Service is filled with all files which should be processed. Those files represent the task for the later working instances and are basically file references.
- From the master node a number of instances are launched within the EC2 environment of AWS. After the start up, each instances will automatically install the WDC framework and launch it.
- Each instance, after starting the framework, will automatically request a task from the SQS and start processing the file.
- The file will first be downloaded from S3 and will then be processed by the worker.
- After finishing one file, the result will be stored in the users own S3 Bucket. And the worker will start again at step 3.
- After the queue is empty, the master can start collecting the extracted data and statistics.
2. Getting Started
Running your own extraction using the WDC Extraction Framework is rather simple and you only need a few minutes to set yourself up. Please follow the steps below and make sure you have all the requirements in place.
2.1. Requirements
In order to run an extraction using the WDC Framework the following is required:
- Amazon Web Service Account/User: As the framework is currently tailored to be run using services from Amazon, you will need to have an AWS with sufficient amount of credits. The user needs rights to access the AWS Services: EC2, S3, SQS and Simple DB.
- AWS Access Token: In order to make use of the Amazon services through the framework you need have your AWS
Access Key Idas well as yourSecret Access Key. Both is available through the Web Interface of AWS in the section IAM (See AWS IAM Docs). In case you do not have access to this section with your user, contact the administrator of your AWS account. - Java: One machine has to serve as master node. This machine, no matter if it is your local server/computer or an EC2 instance within AWS, needs to have Java 6 or higher (latest version runs on Java 8) installed to run the commands and control the extraction, e.g.:
add-apt-repository -y ppa:webupd8team/java
apt-get update
sudo apt-get install oracle-java8-installer - Maven: In order to compile your own version of the framework you need to have Maven3 in place. Building the project with Maven2 will not work, as the project makes use of certain plugins, which are unknown to version 2 of Maven:
apt-get install maven - Git/SVN (optional): In order to checkout the code, you need git or subversion installed:
apt-get install subversion OR apt install git
2.2. Building the code
Below you find a very detailed step by step description how to build the WDC Extraction Framework:
- Create a new folder for the repository and navigate to the folder:
mkdir ~/framework
cd ~/framework - Download the code of the framework from the Github.com WDCFramework Repository or perform the command git clone https://github.com/Web-based-Systems-Group/StructuredDataProfiler.git. Replace git clone with svn checkout if you have subversion installed.
- Create a copy of the
dpef.properties.distfile within the/src/main/resourcesdirectory and name itdpef.properties. Within this file, all needed properties/configurations are stored:cp extractor/src/main/resource/dpef.properties.dist extractor/src/main/resource/dpef.properties - Go through the file carefully and at least adjust all properties marked with
TODO. Each property is described in more detail within the file. The most important properties are listed below:awsAccessKeyandawsSecretKey: Those keys are mandatory to get access to the AWS API and run any commands.resultBucketanddeployBucket: Those S3 buckets will be used in the framework to store the results of the extraction and to store the packages .jar file for later deployment on any launched instance. You can create the buckets either via the Web Interface or using the command line tools3cmd:apt-get install s3cmd
s3cmd --configure
s3cmd mb s3://[resultbucketname]
s3cmd mb s3://[deploybucketname]ec2instancetype: Defines the type of EC2 instances which will be launched. In order to find out which instance type suits your needs best, visit the ec2 instance type website. Former extractions by the WebDataCommons team were mainly done usingc1.xlargeinstances.
Please note that the files of the current version of Common Crawl can be found in the S3 bucketcommoncrawlwhile the Common Crawl data bucket iscrawl-data. Thus the property configuration should be as follows:dataBucket = commoncrawl
dataPrefix = crawl-data
--bucket-prefix CC-MAIN-[...]/segments/[...]/warc/ (for October 2016: CC-MAIN-2016-44/segments/1476988717783.68/warc/)processorClass: This property defines which class is used for the extraction. So far three classes are implemented, which were used to run the former extractions of the WebDataCommons team:org.webdatacommons.hyperlinkgraph.processor.WatProcessor, which was used to extract the hyperlink graph from the .wat files of the Spring 2014 Common Crawl dataset.org.webdatacommons.structureddata.processor.ArcProcessor, which was used to extract the RDFa, Microdata and Microformats from the .arc files of 2012 Common Crawl dataset.org.webdatacommons.structureddata.processor.WarcProcessor, which was used to extract the RDFa, Microdata and Microformats from the .warc files of the November 2013/2014/2015 Common Crawl dataset.org.webdatacommons.webtables.processor.WarcProcessor, which was used to extract the Web Tables from the .warc files of the July 2015 Common Crawl dataset. This code was mainly derived from the Dresden Web Tables Corpus repositories (Extractor|Tools).
org.webdatacommons.framework.processor.FileProcessorinterface.
- Package the WDC Extraction Framework using Maven. Make sure you are using Maven3, as earlier versions will not work.
Note: When packaging the project for the first time, a large number of libraries will be downloaded into your .m2 directory, mainly from breda.informatik.uni-mannheim.de, which might take some time.mvn package
After successfully packaging the project, there should be a new directory, namedtargetwithin your root directory of the project. Besides others, this directory should include the packaged .jar file:dpef-*.jar
2.3 Running your first extraction
After you have packaged the code you can use the bin/master bash script to start and steer your extraction. This bash scripts calls functions implemented within the org.webdatacommons.framework.cli.Master class. To execute the script you need to make it executable:
chmod +x bin/master- Deploy to upload the JAR to S3:
./bin/master deploy --jarfile target/dpef-*.jar - Queue to fill the extraction queue with the Common Crawl files you want to process:
Please note, that the queue command is just fetching files within one folder. In case you need files located in different folders use the bucket prefix file option of the command. You can also limit the number of files pushed to the queue./bin/master queue --bucket-prefix CC-MAIN-2013-48/segments/1386163041297/wet/ - Start to launch EC2 extraction instances from the spot market. The command will keep starting instances until it is cancelled, so beware! Also, the price limit has to be given. The current spot prices can be found at http://aws.amazon.com/ec2/spot-instances/#6. A general recommendation is to set this price at about the on-demand instance price. This way, we will benefit from the generally low spot prices without our extraction process being permanently killed. The price limit is given in US$.
Note: It may take a while (approx. 10 Minutes) for the instances to become available and start taking tasks from the queue. You can observe the process of the spot requests within the AWS Web Dashboard../bin/master start --worker-amount 10 --pricelimit 0.6 - Monitor to monitor the process including the number of items in the queue, the approximate time to finish, and the number of running/requested instances
./bin/master monitor - Shutdown to kill all worker nodes and terminate the spot instance requests
./bin/master shutdown - Retrieve Data to retrieve all collected data to a local directory
./bin/master retrievedata --destination /some/directory - Retrieve Stats to retrieve all collected data statistics to a local directory from the Simple DB of AWS
./bin/master retrievestats --destination /some/directory - Clear Queue to remove all remaining tasks from the queue and delete them
./bin/master clearqueue - Clear Data to remove all collected data from the Simple DB
./bin/master cleardata
org.webdatacommons.framework.cli.Master.
3. Customize your extraction
In this section we show how to build and run your own extractor. For this task we think about a large number of text files (plain .txt files), where each line consists of a number of chars. We are interested in all lines which only consists of numbers (matching the regex pattern [0-9]+). We want to extract those "numeric" lines to a new file and in addition we want to have two basic statistics about each file: the total number of lines of the parsed file and the number of lines which match our regex within the parsed file.
3.1. Basics
Building your own extractor is easy. The core of each extractor is a so called processor within the WDC Extraction Framework. The processor in general gets an input file from the queue and processes it, stores statistics and handles the output. The framework itself takes care of the parallelization and administrative tasks like orchestrating the tasks. Therefore each processor needs to implement he FileProcessor.java interface:
package org.webdatacommons.framework.processor;The interface is fairly simple, as it only contains one method, which receives a
import java.nio.channels.ReadableByteChannel; import java.util.Map;
public interface FileProcessor {
Map<String, String> process(ReadableByteChannel fileChannel, String inputFileKey) throws Exception;
}
ReadableByteChannel, representing the file to process and the files name as input. As result the method returns a Map<String, String> of key value pairs containing statistics of the processed file. The returned key value pairs are written to the AWS Simple DB (see property sdbdatadomain of the dpef.properties). In case you do not need any statistics you can also return an empty Map.
In addition, the WDC Extraction Framework offers a context class, named
ProcessingNode.java, which allows the extending class to make use of contextual settings (e.g. AWS Services to store files). In many cases it makes sense to first have a look into this class before thinking about your own solution.
3.2. Building your own extractor
We create the TextFileProcessor.java which implements the necessary interface and extends the ProcessingNode.java to make use of the context (see line 14).
The class will process a text file, read each line, and check if the line consists only of digits. Lines matching this requirement will be written into a new output file:
1 package org.webdatacommons.example.processor; 2 import java.io.BufferedReader; 3 import java.io.BufferedWriter; 4 import java.io.File; 5 import java.io.FileWriter; 6 import java.io.InputStreamReader; 7 import java.nio.channels.Channels; 8 import java.nio.channels.ReadableByteChannel; 9 import java.util.HashMap; 10 import java.util.Map; 11 import org.jets3t.service.model.S3Object; 12 import org.webdatacommons.framework.processor.FileProcessor; 13 import org.webdatacommons.framework.processor.ProcessingNode; 14 public class TextFileProcessor extends ProcessingNode implements FileProcessor {The code processes the file in the following way:
15 @Override 16 public Map<String, String> process(ReadableByteChannel fileChannel, 17 String inputFileKey) throws Exception { 18 // initialize line count 19 long lnCnt = 0;
20 // initialize match count 21 long mCnt = 0;
22 // Creating a buffered reader from the input stream - the channel is not compressed 23 BufferedReader br = new BufferedReader(new InputStreamReader
(Channels.newInputStream(fileChannel))); 24 // Create a temporal file for our output 25 File tempOutputFile = File.createTempFile( 26 "tmp_" + inputFileKey.replace("/", "_"), ".digitsonly.txt"); 27 // we delete it on exit - so we do not flood the hard drive 28 tempOutputFile.deleteOnExit(); 29 // Create the writer for the output 30 BufferedWriter bw = new BufferedWriter(new FileWriter(tempOutputFile)); 31 while (br.ready()){ 32 // reading the channel line by line 33 String line = br.readLine(); 34 lnCnt++; 35 // Check if the line match our pattern 36 if (line != null && line.matches("[0-9]+")){ 37 mCnt++; 38 // write the line to the output file 39 bw.write(line); 40 } 41 } 42 br.close(); 43 bw.close();
44 // Now the file is parsed completely and the output needs to be stored to s3 45 // create an s3 object 46 S3Object dataFileObject = new S3Object(tempOutputFile); 47 // name the file 48 String outputFileKey = inputFileKey.replace("/", "_") + "digitsonly.txt"; 49 // set the name 50 dataFileObject.setKey(outputFileKey); 51 // put the object to the result bucket 52 getStorage().putObject(getOrCry("resultBucket"), dataFileObject); 53 // create the statistic map (key, value) for this file 54 Map<String, String> map = new HashMap<String, String>(); 55 map.put("lines_total", String.valueOf(lnCnt)); 56 map.put("lines_match", String.valueOf(mCnt)); 57 return map; 58 } 59 }
- Line 18 to 21
- Initializing basic statistic counts.
- Line 22 to 23
- Creating a
BufferedReaderfrom theReadableByteChannel, which makes it easy to read the input file line by line. - Line 24 to 30
- Creating a
BufferedWriterfor a temporal file, which will be deleted as soon as we exit it. This ensures that the hard drive will not be flooded, when processing a large number of files or large files. - Line 31 to 43
- Processing the current file line by line, counting each line. In case a line matches the regex ([0-9]+), the line is written - as it is - into the output file and the corresponding counter is increased.
- Line 44 to 52
- Writing the output file, which includes only the lines consisting of numbers to S3 using the context from the
ProcessingNode. - Line 53 to 56
- The two basic statistics, number of lines and number of matching lines are put into the map and returned by the function. The statistics are written into the AWS Simple DB automatically by the invoking method.
3.3. Configure and package your new extractor
As the extractor is implemented, you need to adjust the dpef.properties file before packaging your code again. First, the new processor needs to be included:
processorClass = org.webdatacommons.example.processor.TextFileProcessordataSuffix = .txt3.4. Limitations
Although the current version of the WDC Extraction Framework allows a straightforward customization for various kinds of extractions, there are some limitations/restrictions which are not (yet) addressed within this version:
- In general, the framework is tailored to be used with AWS only as it depends on key services provided by AWS, the SQS and S3.
- Input files, which should be processed need to be stored and available within AWS S3. The framework currently does not allow you to queue and process files stored.
- Statistics, created while processing files will be stored with AWS SimpleDB. At the moment is not possible to switch this option on/off or change the location, e.g. to an own data base.
4. Former extractors
Some of the datasets, which are available at the Web Data Commons website were extracted using a previous, not that framework-like version of the code. In case, you want to re-run some of the former extractions, or need some inspiration on how to processes certain types of files (e.g. .arc, .warc., ...), the code is still available within the WDC repository below Extractor/trunk/extractor.
5. Costs
The usage of the WDC framework is free of charge. Nevertheless, as the framework makes use of services from AWS, Amazon will charge you for the usage. There are several granting possibilities by Amazon itself, where Amazon supports ideas and projects running within their cloud system with free credits - especially in the education area (see Amazon Grants).
6. License
The Web Data Commons extraction framework can be used under the terms of the Apache Software License.
7. Feedback
Please send questions and feedback to the Web Data Commons mailing list or post them in our Web Data Commons Google Group.
More information about Web Data Commons is found here.