This page describes the data format that is used to represent table data. Further, it contains the download instructions for the WDC Web Table Corpora 2015. General information about the WDC Web Table Corpus 2015 can be found on the overview page.
1. Data Format
As data format, we use JSON containing not only the table data but also meta- and context information. Figure 1 shows an exmaple Web table about soccer clubs, the section below shows the resulting JSON file. The relation object represents the Web table itself in a column wise format. Each array of the object contains the content of one column, this holds for both horizontal and vertical tables. For horizontal tables, this means each array covers all values belonging to one attribute. Further, the basic information like the page title, title of the table (if present) and url are listed together with some administrative data like the offset and s3Link. Since we do not only parse the table, all computed information, e.g. the table type, orientation, header and key column is also included, see extraction description for further details.
Whenever we speak about an index, e.g. headerRowIndex or keyColumnIndex, the index starts at 0. We apply our own header detection which sets hasHeader to true if we found a header and indicates the according header row in headerRowIndex. The field headerPosition which is in this example set to "FIRST_ROW" represtens the original header detection from the DWCT group. Since they only have a look at HTML header-tags in a table which are rarely used, we added our header detection but kept this header detection for compatibility. In our example, the header for attributes is the first row consisting of the values "#","Club","Country","Points" while the key column is the second column "Club","Barcelona","Real Madrid","Bayern München","Paris Saint Germain","Atlético Madrid","Juventus","Manchester City","Arsenal","FC Porto","Manchester United".
All contextual information like the timestamps and the surrounding words are contained. We applied a simple heuristic to exclude HTML tags from the sourrounding text. Note that the timestamps are extracted from the previous resp. following paragraph (text within next next HTML paragrpah tag) which does not need to correspond to timestamps found in the sourrounding 200 words, e.g. another table follows and not a paragrpah. Note that the table does not have a caption, that is why the title object is empty.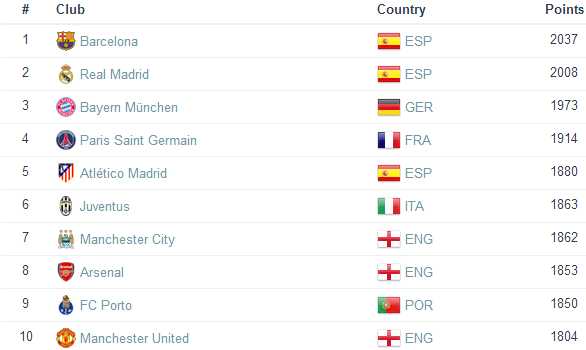
Fig. 1: Example Web table of soccer clubs
{ "relation":[ ["#","1","2","3","4","5","6","7","8","9","10"], ["Club","Barcelona","Real Madrid","Bayern München","Paris Saint Germain","Atlético Madrid","Juventus","Manchester City","Arsenal","FC Porto","Manchester United"], ["Country","ESP","ESP","GER","FRE","ESP","ITA","ENG","ENG","POR","ENG"], ["Points","2037","2008","1973","1914","1880","1863","1862","1853","1850","1804"] ] "pageTitle": "FootballDatabase - Club Rankings and Statistics", "title": "", "url": "http://footballdatabase.com/index.php?page\u003dplayer\u0026Id\u003d660", "hasHeader": true, "headerPosition": "FIRST_ROW", "tableType": "RELATION", "tableNum": 0, "s3Link": "common-crawl/crawl-data/CC-MAIN-2015-32/segments/1438042981460.12/warc/CC-MAIN-20150728002301-00000-ip-10-236-191-2.ec2.internal.warc.gz", "recordEndOffset": 99246001, "recordOffset": 99230046, "tableOrientation": "HORIZONTAL", "TableContextTimeStampBeforeTable": "{10283\u003dOn Wednesday, December 6, 2006 Islanders General Manager Garth Snow attended the Fifth Annual John Theissen Holiday Fundraiser.}", "TableContextTimeStampAfterTable": "{37811\u003dIn 2005, Slovakian champion FC Artmedia upset 39-time Scottish league champion Celtic 5-0 in their European Champions League second-round qualifying match.}", "lastModified": "Sat, 19 Jun 2010 15:14:57 GMT", "textBeforeTable": "Chelsea Ronnie MacDonald Bayern München Peter P. Juventus Mitsurinho Real Madrid Jan S0L0 Barcelona Globovision Football", "textAfterTable": "Full World Ranking Match Centre Argentina Primera 2015 26 July 2015 Vélez Sarsfield 0 - 2 Olimpo Brazil Serie A 2015 26 July 2015 Vasco da Gama 1 - 4 Palmeiras Mexico Liga", "hasKeyColumn": true, "keyColumnIndex": 1, "headerRowIndex": 0 }
2. Download
We provide 3 different downloads: the complete Web Table Corpus containing all tables types (also entity and relational tables), the relational Web Table Corpus and the English Web Table Corpus. The complete corpus is divided into 99 archives. Each archive in the complete corpus contains one folder with JSON files describing Web tables extracted from a couple thousand Web pages. Similar holds for the relational corpus also consisting of 99 archives. The English Web Table Corpus consists of 51 archives where each archive covers about 1 million JSON files. In contrast to the other two downloads, one JSON file only describes one Web table.
To download the corpora of Web tables use the following links:
| Data Set | Size | #Files |
|---|---|---|
| Complete Corpus 2015 | 165 GB | 99 (.tar) |
| Relational Corpus 2015 | 69 GB | 99 (.tar) |
| English-Language Relational Web Tables 2015 | 69 GB | 51 (.tar) |
You can download a data sample from the complete corpus on the following link:
3. Feedback
Please send questions and feedback to the Web Data Commons mailing list or post them in our Web Data Commons Google Group.
More information about Web Data Commons is found here.
4. Credits
The extraction of the Web Table Corpus was supported by an Amazon Web Services in Education Grant award.
