A subset of the HTML tables on the Web contains relational data which can be useful for various applications. The Web Data Commons project has extracted two large corpora of relational Web tables from the Common Crawl and offers them for public download. This page provides an overview of the corpora as well as their use cases.
News
- 2017-06-26: We have released the Web Data Integration Framework (WInte.r), which provides parsers and methods for the integration of Web Tables.
- 2017-02-07: A second version of the T2D gold standard T2Dv2 has been released.
- 2016-10-15: Paper about Matching Web Tables To DBpedia - A Feature Utility Study has been accepted at the EDBT'17 conference in Venice, Italy.
- 2016-02-01: Poster about A Large Public Corpus of Web Tables containing Time and Context Metadata (poster) has been accepted as poster at the WWW'16 conference in Montréal, Canada.
- 2015-12-15: Paper about Profiling the Potential of Web Tables for Augmenting Cross-domain Knowledge Bases has been accepted at the WWW'16 conference in Montréal, Canada.
- 2015-12-01: Added context information described in the WDC Web Table Corpus 2015 Extraction to the Entity-level Gold Standard of the T2D Gold Standard.
- 2015-11-19: WDC Web Table Corpus 2015 released consisting of 233 million Web tables extracted from the July 2015 Common Crawl.
- 2015-04-01: T2D Gold Standard for comparing matching systems on the task of finding correspondences between Web tables and large-scale knowledge bases released.
- 2015-02-25: Dresden Web Table Corpus published containing 125 million data tables extracted from the July 2014 version of the Common Crawl.
- 2014-10-27: Tables corpus is used by Mannheim Search Join Engine which wins prize at Semantic Web Challenge 2014.
- 2014-03-05: WDC Web Table Corpus 2012 released consisting of 147 million relational Web tables extracted from the August 2012 Common Crawl.
Contents
1. About the WDC Web Table Corpora
The Web contains vast amounts of HTML tables. Most of these tables are used for layout purposes, but a small subset of the tables is relational, meaning that they contain structured data describing a set of entities. The Web Data Commons project extracts relational Web tables from the Common Crawl, the largest and most up-to-data Web corpus that is currently available to the public. The resulting Web table corpora are provided for public download. In addition, we calculate statistics about the structure and content of the tables.
Up till now, we have extracted two Web table corpora from the Common Crawl:
- WDC Web Table Corpus 2015
- extracted from the July 2015 Common Crawl containing 1.78 billion HTML pages originating from 15 million pay-level domains.
- the corpus contains 233 million Web tables which are classified into the categories: relational, entity, and matrix.
- the corpus contains metadata for each table including table orientation, header rows, key columns
- the corpus contains context information for the table such as the title of the HTML page, the caption of the table, the text before and after the table, and timestamps from the page.
- WDC Web Table Corpus 2012
- extracted from the 2012 Common Crawl containing 3.5 billion HTML pages originating from 40 million pay-level domains.
- the corpus contains 147 million Web tables.
- the corpus does not contain metadata about table orientation, header rows, and key columns, as well as no table context data.
2. Application Potential of Web Tables
This Section gives an overview of existing research on employing Web tables within various application domains as well as empirical studies about the amount and content of relational tables on the Web. The first step towards understanding Web tables is to detect relational tables [Wang2002]. Initial studies by Cafarella et al. [Cafarella2008] showed that out of 14 billion HTML tables in the Google crawl, 154 million tables contained relational data (1.1%). In [Crestan2011], the authors provide a fine-grained classification of the different types of HTML tables that are found on the Web based on the Bing Web crawl. [Hassanzadeh2015] identifies the topical distribution of Web table data by matching tables to different cross-domain knowledge bases.
Recently, a body of interesting research has developed around exploiting relational Web tables for the following applications:
- Data Search: A user that is in need for some data is likely to find a table containing the desired data somewhere on the Web. [Cafarella2009], [Venetis2011], and [Pimplikar2012] propose methods for finding matching tables given a set of keywords describing the information need. An example of a table search service is Google Table Search which allows users to search for Web tables as well as public Google Fusion Tables [Balakrishnan2015]. [Tam2015] formalize the requirements for Web table search and present algorithms to solve the connected problems.
- Table Extension/Completion: [Cafarella2009], [Yakout2012], [Bhagavatula2013], [DasSarma2012], [Bizer2014], [Lehmberg2014] and [Lehmberg2015] propose methods for extending a local table with additional columns based on the corpus of tables that are published on the Web. A user having a local table describing countries could for instance use these methods to have columns containing the population, area total, and the capital of each country added to his table. [Ahmadov2015] try to fill missing values in existing tables.
- Knowledge Base Construction: The data contained in Web tables can also be used to construct or extend general-purpose knowledge bases such as DBpedia, Freebase or YAGO. [Zhang2013] propose a method for extending the DBpedia knowledge base with data from Web tables. [Sekhavat2014] introduce a probabilistic approach for extending YAGO by exploiting natural language patterns. [Wang2012] propose a method for building a comprehensive knowledge base using linguistic patters to extract a probabilistic taxonomy of classes and entities from Web texts and add facts about the attributes of the entities using Web tables afterwards. Biperpedia [Gupta2014] has been created by exploiting query stream and applying the learnt extractors. The Knowledge Vault [Dong2014] extends Freebase using Web tables data amongst other types of Web data. An overview of knowledge base construction approaches using Web sources is given by Weikum and Theobald [Weikum2010].
- Table Matching: For most applications, the matching of Web tables plays an important role and is discussed in different works. [Limaye2010], [Mulwad2010] propose frameworks to annotate the Web tables with entities, properties and types from knowledge bases. [Ritze2015] introduce an simultaneous schema- and instance matching approach to annotate rows with entities, columns with properties and tables with types. Other methods further exploit the context [Wang2015], [Braunschweig2015] as well as timestamps [Zhang2013]. In addition to fully automatic approaches, crowdsourcing can support the matching process [Fan2014], [Chu2015].
- NLP Tasks: The table corpus could also be useful for various natural language processing tasks as the things that appear in the same column are often closely related to each other, which for example can be exploited for disambiguation.
3. WDC Web Table Corpus 2015
This Section describes the methodology that was used to extract the July 2015 Web Table Corpus and links to pages containing detailed statistics about the corpus as well as download instructions. The July 2015 Common Crawl corpus contains 1.78 billion HTML documents from over 15 million pay-level domains.
We employ the DWTC framework from the Database Technology Group at the University of Dresden to extract HTML tables from the crawl and to distinguish between different types of Web tables, e.g. relational and layout tables. The table type assignment works in two steps: filtering and classification.
First, the framework filters out all HTML tables that are not innermost tables, i.e., that contain tables in their cells, and all tables contain less than 2 columns or 3 rows. Further, the framework looks at other criteria such as sparseness of the table, average attribute size, number of links etc. This step discards most of the HTML tables that we consider as non-genuine. Altogether, we parsed 1.78 billion HTML pages from the Common Crawl July 2015 Web corpus. In these pages we found a total of 10.24 billion innermost tables, i.e., an average of 5.75 innermost tables per page. After the filtering step, 233 million tables remain. A content-based deduplication is not performed.
Second, the framework parses the tables and classifies them as Relational, Entity, Matrix and Layout [Eberius2015]. Figure 1 shows examples of the first three table types. Relational tables (1.a) describe a set of similar entities (here: lakes) with one or more attributes (area). The name of the entity, also called key, is contained in the table. In contrast, entity tables (1.b) only describe one entity with one or more attributes. The name of this entity is usually not contained in the table but may be found in the table context. A common example of entity tables are tables containing product details (but not the product name) on shopping websites. The third table type matrix (1.c) is most often used for results of statistical evaluations.
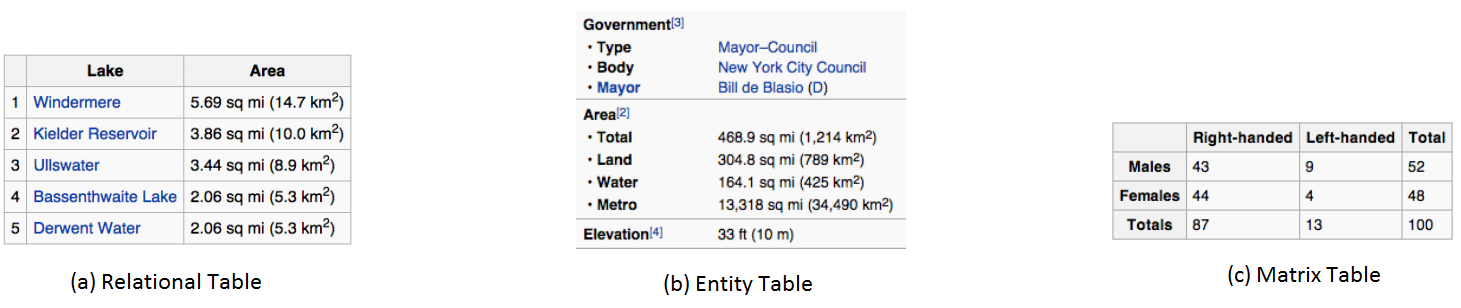
Fig. 1: Examples of the three table types extracted from the English Wikipedia [Braunschweig2015a]
The classification into the different types uses a mixture of global and local features, see [Braunschweig2015a] for more details. The global features include average and standard deviation of the column and row count as well as the average cell length. Additionally, it computes content ratios (image, alphabetical and digit) and cumulative content type length consistencies of the rows and columns [Crestan2011, Wang2002]. The local features are local average length, local length variance and local content ratio of cells. Table 1 shows the distribution of the resulting table types. Altogether, 90,266,223 tables were classified as relational tables (0.9%) which is in line with the results by Cafarella et al. [Cafarella2008] (1.1%) and the results of our previous extraction (1.3%).
| #Type | #Tables | % of all tables |
|---|---|---|
| Relational | 90,266,223 | 0.90 |
| Entity | 139,687,207 | 1.40 |
| Matrix | 3,086,430 | 0.03 |
| Sum | 233,039,860 | 2.25 |
On top of the DWTC framework, we implemented methods to determine the orientation of a table, i.e., Horizontal or Vertical, the header row, the key column (if existant), as well as methods to extract context data from the page content around the Web table.
Table Orientation: In horizontal tables, the attributes are represented in the columns while in vertical tables the attributes are described in rows, e.g. as shown in Figure 1a. The determination of the table orientation bases on the idea that for horizontal tables, the cells in one column have a similar length because they belong to the same attribute. In contrast, the opposite holds for vertical tables where cells in one row typically have a similar length. We determine the orientation of a table by computing the standard deviation (STD) of the cell length for each row and column. If the average STD for columns is smaller than the average STD for rows, we define the table as horizontal and otherwise as vertical.
Header Row Detection: For the description of our header row detection, we always assume to have a horizontal table but of course can also be applied on vertical tables. We define a header row as the row containing the attribute names, e.g. the first row in Figure 1a with the attribute names 'Lake' and 'Area'. Our header detection bases on the idea that a header row shows a different characteristic than the following rows. Therefore, we analyze the rows by building a content pattern for each cell in a row. A cell content pattern is a strining together of the following classes: alphabetical (A), digit (D), punctuation (P) and special character (S). For example, a cell with the content "area" has the content pattern "AAAA" while a cell with the content "5.69m" is described by the pattern "DPDDA". Based on these patterns, we can determine the different characteristics of rows and thus we can conclude which row contains the names of the attributes and is in turn considered as the header row.
Key Column Detection: Similar to the header row detection, we assume to have a horizontal table for the key column detection. The key column of a table is said to be the column which contains the names of the entities, e.g. the second column of the table in Figure 1a with the attribute name 'Lake'. Our key column detection bases on the idea that a key column contains a certain amount of unique cell values because it contains the names of different entities. Thus, our main assumption is that the key column covers a high amount of unique cell values. Besides the requirement of having at least 50% unique values, it must be a column mainly consisting of string values and have an average length greater than 3.5 and lower than 200.
Context Data: In order to understand the content of Web tables [Yakout2012] as well as for determining the timeliness of the content, it is beneficial to know the text that appears on the HTML page around the Web table. We thus also extract context related data from the HTML page: HTML page title, table caption, 200 words before as well as after the table, the last modified date in the HTTP header, and sentences in surrounding paragraphs containing timestamps.
We ran the table extraction on Amazon EC2 using 100 AWS c1.xlarge machines, the extraction and table classification together took around 25 hours, which cost around 250 USD. The table below summarizes key figures of the extraction run:
| Crawl Date | July 2015 |
|---|---|
| Crawl Data Volumn | 165 Gigabyte |
| HTML Pages | 1.78 billion |
| Domains in Crawl (PLDs) | 15 million |
| Extracted Tables | 233 million |
| PLDs of Extracted Tables | 323 thousand |
We have calculated statistics for three subsets of the overall table corpus:
- Detailed Statistics about relational tables
- Detailed Statistics about English-language relational tables
- Detailed Statistics about entity tables
An details about the data format that we use to represent the tables as well as instructions on how to download the table corpus are found at
4. WDC Web Table Corpus 2012
This Section describes the methodology that was applied to extract the August 2012 Web Table Corpus from the Common Crawl Web corpus and links to pages containing detailed statistics about the corpus as well as download instructions. The 2012 Common Crawl corpus contains 3.5 billion HTML documents which originate from over 40 million pay-level domains.
[Cafarella2008], [Crestan2011], and [Wang2002] propose classification methods for distinguishing between relational Web tables and other HTML tables. Based on the features proposed in these papers, we implemented a classifier for detecting relational Web tables. The classifier works in two steps. First, it filters out all HTML tables that are not innermost tables, i.e., that contain tables in their cells, and that contain less than 5 cells or 3 rows. This step discards already around 90% of all HTML tables. Second, we parse the remaining tables and classify them as relational or not relational using a mixture of layout and content features. The layout features include the average and the standard deviation of the column count, row count and cell length. Additionally we compute the length consistency of the rows and columns. Content features are the percentages of link, form, image, empty, digit, and text cells. We also compute the content type consistency for rows and columns.Altogether, we parsed 3,301,089,681 HTML pages from the Common Crawl 2012 Web corpus. In these pages we found a total of 11,245,583,889 innermost tables, i.e., an average of 3.4 innermost tables per page. Out of these tables, 147,636,113 were classified as relational tables (1.3%). The tables originate from 101,177,544 different pages. A further classification into entity tables has not been performed.
In order not to miss relational tables, we tuned our classifier for recall at the cost of precision. An evaluation on a test set of several thousand tables showed that only around 60% of the tables classified as relational are actually relational tables (compared to the 80% precision reported in [Cafarella2008]).
We ran the table extraction on Amazon EC2 using 100 AWS c1.xlarge machines, which ran an adapted version of the extraction framework that we also used to extract the WebDataCommons RDFa, Microdata, and Microformat Data Set from the Common Crawl. The extraction and table classification together took around 1,500 machine hours, which cost around 150 USD. The table below summarizes key figures of the extraction run:
| Crawl Date | August 2012 |
|---|---|
| Crawl Data Volumn | 1020 Gigabyte |
| HTML Pages | 3.5 billion |
| Domains in Crawl (PLDs) | 40 million |
| Extracted Tables | 147 million |
| PLDs of Extracted Tables | 1.01 million |
We have calculated statistics for the complete table corpus as well as for the English-language subset:
- Detailed Statistics about relational tables
- Detailed Statistics about English-language relational tables
An details about the data format that we use to represent the tables as well as instructions on how to download the table corpus are found at
4. Source Code
The source code of the extraction framework which has been used for the creation of the July 2015 Web Table Corpus is publicly available. The code builds on the DWTC framework from the Database Technology Group at the University of Dresden which again is partly based on the code that we used to extract the 2012 Web Table Corpus.
5. License
The code can be used under the terms of the Apache software license.
6. Feedback
Please send questions and feedback to the Web Data Commons mailing list or post them in our Web Data Commons Google Group.
General information about the Web Data Commons project is found here.
7. Credits
The extraction of the Web Table Corpus was supported by an Amazon Web Services in Education Grant award.

8. Other Web Data Corpora
In the following, we list other Web data corpora which are accessible to the public:
- Dresden Web Table Corpus containing 125 million data tables extracted from the July 2014 version of the Common Crawl.
- DBpedia as Tables: Tabular representation of the DBpedia knowledge base containing Wikipedia infobox data. The instances of each of the 530 classes in the knowledge base are provided as a seperate table. Altogether the tables cover 4 million entities.
- WikiTables: Corpus consisting of 15 million non-infobox tables extracted from Wikipedia.
- WebDataCommons RDFa, Microdata and Microformat Data Set: RDF data set consisting of 7 billion triples RDFa, Microdata and Microformat which originate from 40 million different websites and have been extracted from the 2012 version of the common crawl. The data can be easily translated into tables (one table per class and website).
- Billion Triples Challenge 2012 Data Set: Corpus consisting of 1.4 billion Linked Data triples that were crawled from around 1000 different Linked Data sources on the Web. The data can be easily translated into tables (one table per class and data source).
- publicdata.eu: Data portal containing references to 46,000 government data sets which are mostly tabular.
- data.gov: Data portal containing 85,000 data sets provided by the US government. The data sets are mostly tabular.
9. References
If you like to cite a reference for the WDC web tables corpus please refer to:
Oliver Lehmberg, Dominique Ritze, Robert Meusel, Christian Bizer: A Large Public Corpus of Web Tables containing Time and Context Metadata. WWW 2016.
- [Cafarella2008] Michael J. Cafarella, Eugene Wu, Alon Halevy, Yang Zhang, Daisy Zhe Wang: WebTables: exploring the power of tables on the Web. VLDB 2008.
- [Crestan2011] Eric Crestan and Patrick Pantel: Web-scale table census and classification. WSDM 2011.
- [Cafarella2009] Michael J. Cafarella, Alon Halevy, and Nodira Khoussainova: Data integration for the relational Web. Proc. VLDB Endow. 2009.
- [Yakout2012] Mohamed Yakout, Kris Ganjam, Kaushik Chakrabarti, and Surajit Chaudhuri: InfoGather: entity augmentation and attribute discovery by holistic matching with Web tables. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data (SIGMOD '12), 2012.
- [Bhagavatula2013] Chandra Sekhar Bhagavatula, Thanapon Noraset, and Doug Downey: Methods for exploring and mining tables on Wikipedia. In Proceedings of the ACM SIGKDD Workshop on Interactive Data Exploration and Analytics (IDEA '13), 2013.
- [Pimplikar2012] Rakesh Pimplikar and Sunita Sarawagi: Answering table queries on the Web using column keywords. Proc. VLDB Endow. 5:10, 2012.
- [DasSarma2012] Anish Das Sarma, Lujun Fang, Nitin Gupta, Alon Halevy, Hongrae Lee, Fei Wu, Reynold Xin, and Cong Yu: Finding related tables. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data (SIGMOD '12), 2012.
- [Zhang2013] Zhang, Xiaolu, et al.: Mapping entity-attribute Web tables to web-scale knowledge bases. In: Database Systems for Advanced Applications. Springer, 2013.
- [Wang2012] Jingjing Wang, Haixun Wang, Zhongyuan Wang, and Kenny Q. Zhu: Understanding tables on the Web. In Proceedings of the 31st international conference on Conceptual Modeling (ER'12), 2012.
- [Wang2002] WANG, Yalin; HU, Jianying: Detecting tables in html documents. In: Document Analysis Systems V. Springer Berlin Heidelberg, 2002.
- [Chen2013] Zhe Chen and Michael Cafarella: Automatic Web spreadsheet data extraction. In Proceedings of the 3rd International Workshop on Semantic Search Over the Web. 2013.
- [Bizer2014] Christian Bizer: Search Joins with the Web. Invited Lecture at the International Conference on Database Theory (ICDT2014). 2014.
- [Lehmberg2014] Oliver Lehmberg, Dominique Ritze, Petar Ristoski, Kai Eckert, Heiko Paulheim and Christian Bizer: Extending Tables with Data from over a Million Websites (Slides, Video). Semantic Web Challenge 2014, Riva del Garda, Italy, October 2014.
- [Balakrishnan2015] Sreeram Balakrishnan, Alon Halevy, et al.: Applying WebTables in Practice. Conference on Innovative Data Systems Research (CIDR). 2015.
- [Morcos2015] John Morcos, Ziawasch Abedjan, Ihab Francis Ilyas, Mourad Ouzzani, Paolo Papotti, Michael Stonebraker: DataXFormer: An Interactive Data Transformation Tool. SIGMOD '15 Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. 2015.
- [Lehmberg2015] Oliver Lehmberg, Dominique Ritze, Petar Ristoski, Robert Meusel, Heiko Paulheim, Christian Bizer: The Mannheim Search Join Engine. Journal of Web Semantics, 2015 (In Press).
- [Venetis20111] Petros Venetis, Alon Halevy, Jayand Madhavan, Marius Pasca, Warren Shen, Fei Wu, Gengxin Miao, Chung Wu: Recovering Semantics of Tables on the Web. Proceedings of the VLDB Endow., 2011.
- [Tang2006] Kai-Tai Tang, Howard Leung: Reconstructing the correct writing sequence from a set of chinese character strokes. Springer-Verlag Berlin, Heidelberg 2006.
- [Sekhavat2014] Yoones A. Sekhavat, Francesco di Paolo, Denilson Barbosa, Paolo Merialdo: Knowledge Base Augmentation using Tabular Data. Proceedings of LDOW, 2014.
- [Ritze2015] Dominique Ritze, Oliver Lehmberg, Christian Bizer: Matching HTML Tables to DBpedia Proceedings of the 5th International Conference on Web Intelligence, Mining and Semantics, 2015.
- [Limaye2010] Girija Limaye, Sunita Sarawagi, Soumen Chakrabarti: Annotating and Searching Web Tables Using Entities, Types and Relationships Proceedings of the VLDB Endowment, 2010.
- [Hassanzadeh2015] Oktie Hassanzadeh, Michael J. Ward, Mariano Rodriguez-Muro, Kavitha Srinivas: Understanding a Large Corpus of Web Tables Through Matching with Knowledge Bases – An Empirical Study Proceedings of the OM Workshop, 2015.
- [Weikum2010] Gerhard Weikum, Martin Theobald: From Information to Knowledge: Harvesting Entities and Relationships from Web Sources Proceedings of the PODS, 2010.
- [Dong2014] Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, Wei Zhang: Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion Proceedings of the KDD, 2014.
- [Gupta2014] Rahul Gupta, Alon Halevy, Xuezhi Wang, Steven Euijong Whang, Fei Wu: Biperpedia: An Ontology for Search Applications Proceedings of VLDB Endowment, 2014.
- [Zhang2013] Meihui Zhang, Kaushik Chakrabarti: InfoGather+:Semantic Matching and Annotation of Numeric and Time-Varying Attributes in Web Tables Proceedings of SIGMOD, 2013.
- [Braunschweig2015] Katrin Braunschweig, Maik Thiele, Julian Eberius, Wolfgang Lehner: Column-specific Context Extraction for Web Tables Proceedings of SAC, 2015.
- [Tam2015] Nguyen Thanh Tam, Nguyen Quoc Viet Hung, Matthias Weidlich, Karl Aberer: Result Selection and Summarization for Web Table Search Proceedings of the 31st International Conference on Data Engineering, 2015.
- [Fan2014] Ju Fan, Meiyu Lu, Beng Chin Ooi, Wang-Chiew Tan, Meihui Zhang: A Hybrid Machine-Crowdsourcing System for Matching Web Tables Proceedings of the 30st International Conference on Data Engineering, 2014.
- [Mulwad2010] Varish Mulwad, Tim Finin, Zareen Syed, Anupam Joshi: Using linked data to interpret tables Proceedings of the 1st International Workshop on Consuming Linked Data, 2010.
- [Wang2015] Hong Wang, Anqi Liu, Jing Wang, Brian D. Ziebart, Clement T. Yu, Warren Shen: Context Retrieval for Web Tables Proceedings of the ICTIR, 2015.
- [Chu2015] Xu Chu, John Morcos, Ihab F. Ilyas, Mourad Ouzzani, Paolo Papotti, Nan Tang, Yin Ye: KATARA: A Data Cleaning System Powered by Knowledge Bases and Crowdsourcing Proceedings of the SIGMOD, 2015.
- [Braunschweig2015a] Katrin Braunschweig: Recovering the Semantics of Tabular Web Data PhD Thesis, 2015.
- [Eberius2015] Julian Eberius, Katrin Braunschweig, Markus Hentsch, Maik Thiele, Ahmad Ahmadov, Wolfgang Lehner: Building the Dresden Web Table Corpus: A Classification Approach Proceedings of the 2nd International Symposium on Big Data Computing (BDC), 2015.
- [Ahmadov2015] Ahmad Ahmadov, Maik Thiele, Julian Eberius, Wolfgang Lehner, Robert Wrembel: Towards a Hybrid Imputation Approach Using Web Tables Proceedings of the 2nd International Symposium on Big Data Computing (BDC), 2015.