WebIsADb is a publicly available database containing more than 400 million hypernymy relations we extracted from the CommonCrawl web corpus. This collection of relations represents a rich source of knowledge and may be useful for many researchers. We offer the tuple dataset for public download and an application programming interface to help other researchers programmatically query the database.
News
- 2016-05-30: WebIsADb involved @OKE2016 @ESWC2016
S. Faralli and S. P. Ponzetto. DWS at the 2016 Open Knowledge Extraction Challenge: A Hearst-like Pattern-Based Approach to Hypernym Extraction and Class Induction.
Candidated as ESWC 2016 Best Challenges Paper:

- 2016-01-01: A paper about the WebIsADb was accepted at LREC 2016
 .
.
Julian Seitner, Christian Bizer, Kai Eckert, Stefano Faralli, Robert Meusel, Heiko Paulheim and Simone Paolo Ponzetto, 2016. A Large Database of Hypernymy Relations Extracted from the Web. Proceedings of the 10th edition of the Language Resources and Evaluation Conference. Portorož, Slovenia.
Contents
1. WebIsADb
Our approach to "isa" relation extraction can be divided in three main steps:
Table 1: The list of patterns used for the tuples extraction
(NPt indicates the hyponym and NPh the hypernym). For
each pattern we also report the estimated precision and
the number of resulting matches.
| Pattern | Precision | # match |
|---|
| NPt and any other NPh | 0.76 | 975,735 |
| NPt and other NPh | 0.70 | 45,900,092 |
| NPt or other NPh | 0.70 | 13,392,348 |
| NPt is adjsup NPh | 0.63 | 6,150,245 |
| NPt is adjsup most NPh | 0.63 | 2,286,478 |
| NPh such as NPt | 0.58 | 70,337,543 |
| such NPh as NPt | 0.58 | 5,755,389 |
| NPt are a NPh | 0.57 | 15,141,131 |
| NPt and some other NPh | 0.54 | 296,524 |
| NPt which is called NPh | 0.50 | 119,317 |
| NPt are adjsup most NPh | 0.49 | 860,770 |
| examples of NPh are NPt | 0.45 | 267,764 |
| NPt, kinds of NPh | 0.45 | 4,618,873 |
| NPh including NPt | 0.44 | 80,640,885 |
| NPt is a NPh | 0.44 | 187,644,160 |
| NPh other than NPt | 0.44 | 7,175,087 |
| NPt were a NPh | 0.42 | 3,206,238 |
| NPt are adjsup NPh | 0.41 | 1,393,484 |
| NPt was a NPh | 0.39 | 39,585,428 |
| NPt, one of the NPh | 0.38 | 4,200,376 |
| NPt is example of NPh | 0.36 | 292,706 |
| examples of NPh is NPt | 0.33 | 267,021 |
| NPh e.g. NPt | 0.33 | 1,973,022 |
| NPt, forms of NPh | 0.33 | 3,326,957 |
| NPt like other NPh | 0.31 | 402,388 |
| NPh for example NPt | 0.31 | 2,356,522 |
| adjsup most NPh is NPt | 0.31 | 2,999,877 |
| NPt or the many NPh | 0.31 | 15,192 |
| NPh i.e. NPt | 0.29 | 2,114,793 |
| NPh which is similar to NPt | 0.29 | 63,713 |
| NPh notably NPt | 0.28 | 1,154,745 |
| NPh which are similar to NPt | 0.28 | 17,304 |
| NPt which is named NPh | 0.26 | 19,122 |
| NPh principally NPt | 0.26 | 455,578 |
| adjsup NPh is NPt | 0.25 | 10,360,953 |
| NPh in particular NPt | 0.25 | 2,354,596 |
| NPh example of this is NPt | 0.25 | 14,237 |
| NPh among them NPt | 0.23 | 524,784 |
| NPh mainly NPt | 0.22 | 4,792,792 |
| NPh except NPt | 0.22 | 9,648,662 |
| adjsup most NPh are NPt | 0.21 | 2,357,968 |
| NPt are examples of NPh | 0.20 | 2,205,089 |
| NPh especially NPt | 0.19 | 20,872,227 |
| adjsup NPh are NPt | 0.19 | 3,755,893 |
| NPh particularly NPt | 0.19 | 11,656,254 |
| NPt, a kind of NPh | 0.18 | 1,452,822 |
| NPt, a form of NPh | 0.18 | 1,127,173 |
| NPt which sound like NPh | 0.18 | 32,730 |
| NPh examples of this are NPt | 0.18 | 1,515 |
| NPt sort of NPh | 0.18 | 7,884,398 |
| NPh types NPt | 0.17 | 11,080,276 |
| NPh compared to NPt | 0.17 | 346,525 |
| NPh mostly NPt | 0.16 | 8,383,063 |
| compare NPt with NPh | 0.16 | 340,636 |
| NPt, one of those NPh | 0.15 | 99,241 |
| NPt, one of these NPh | 0.13 | 53,235 |
| NPt which look like NPh | 0.13 | 68,945 |
| NPh whether NPt or | 0.13 | 2,800,349 |
-
WebDataCommons framework
To extract a large collection of "isa" relations from the Web, we decided to rely on the largest publicly available Web corpus i.e. the crawl corpora provided by the CommonCrawl Foundation. The original corpus contains over 2.1 billion crawled web pages, consisting of over 38000 Web ARChive, ISO 28500:2009 (WARC) files with a total packed size of 168TB. To efficiently extract "isa" relations from the crawl corpora, our implementation of relations extraction directly synchronizes with the framework of the WebDataCommons project; -
Extraction and filtering
The extraction of "isa" relations from text is based on Hearst-like patterns. We collected a set of 59 patterns (see Table 1 for the full list). The patterns identified are then translated into regular expressions which we use to match with the incoming text. In order to test the quality of the above defined regular expressions, we extracted a random 1% portion of the entire corpus and analyzed 100 matches per pattern. With that evaluation, we estimated the precision of each pattern, as shown in Table 1. Patterns with a very low precision have then been excluded before performing the subsequent steps. Since both the Web and the extraction phase are sources of noise, some post-processing and filtering is required. To facilitate a sensible trade-off between coverage and precision, we try to remove only the obvious noise, while keeping as much coverage as possible. This strategy comes from the idea that some task may need ``less precise'' but ``more covering'' data. For supporting use cases where more precision is required, we provide metadata for each tuple, which allows for additional filtering techniques on the client side. As basic filtering techniques, we i) remove duplicates i.e. tuples that occur more than once under the same pay level domain are removed; ii) transform all the capital letters to lower case and removed all leading and trailing punctuations; iii) remove all quotation marks and apostrophes, since apostrophes are frequently used as replacement for quotation marks. The extraction and filtering of the tuples took around 2,200 computing hours and was run using 100 servers in parallel in less than 24 hours; Indexing
To store and access all the extracted relations we created a MongoDB database.
2. Online Demo
To have a direct look at the WebIsA database, a demo Web application is also avaliable here (see Figure 1).
3. Resources
We offer both data and tools to re-generate/access the WebIsADb:
Data
The collection of relations can be downloaded in two formats:MongoDB database:
The database consists of two MongoDB database instances: the first collecting the "isa" tuples (but not the metadata corresponding to the extraction contexts) and the second the extraction contexts (i.e. the pay-level domains and the sentences from where a tuple was extracted). The two database can be separately downloaded and instantiated in the same or in two different machines.- Download the database dumps:
- Tuples: tuples-webisadb-april-2016.tar.gz (204309024768 byte when un-compressed)
- Contexts: contexts-webisadb-april-2016.tar.gz (117844946944 byte when un-compressed)
- Install MongoDB and restore the Tuples and Contexts dumps:
Download and install the MongoDB server (we recommend the installation of the version v3.0.7) on your machine/machines please follow the instructions reported at the official guide Install MongoDB. To instanciate our dumps on your target MongoDB servers, please follow the instructions reported at the official guide Restore a MongoDB database. Our suggestion is to use the "mongorestore" tools by passing as <path to the backup> argument the path to the folders "tuples-webisadb-april-2016" and "contexts-webisadb-april-2016" of the uncompressed dumps for tuples and contexts respectively.
- Download the database dumps:
Comma-separated values files:
- Tuples CSV files:
link description tuplesdb.1.tar.gz all the tuple grouped by the instance string value tuplesdb.2.tar.gz all the tuple grouped by the class string value
The two above archives contain a set of tar file. Each tar file contains a set of "csv" file with the following format: - "286980418": the record identifier of the tuple as in the mongodb instance;
- "aang": the instance string value;
- "character": the class string value;
- "41": number of matches;
- "11": number of matching patterns;
- "32": number of matching pay-level domains;
- modification: is a JSON representation of the list of all the variants of the relation "(aang,character)". Each item of the JSON representation includes:
- ipremod: the pre-modifier of the "instance";
- ipostmod: the post-modifier of the "instance";
- cpremod: the pre-modifier of the "class";
- cpostmod: the post-modifier of the "class";
- frequency: the frequency of the "isa" relation "(ipremod +"aang"+ipostmod, cpremod+"character"+cpostmod)"
- pidspread: the number of matching pattern of the relation "(ipremod +"aang"+ipostmod,cpremod+"character"+cpostmod)";
- pldspread: the number of pay level domains where we extracted the relation "(ipremod +"aang"+ipostmod,cpremod+"character"+cpostmod)";
- pids: a semicolon separeted list of the correpsonding pay-level domains (e.g. including "appszoom.com");
- plds: a semicolon separeted list of the matching pattern labels (e.g. "p1,p25,p10,p8a,p3a" correponding to the following patterns: "NPt and other NPh", "NPh except NPt", "such NPh as NPt", "NPt is a NPh" and "NPh including NPt" respectively);
- provids: a semicolon separeted list of contexts id, one can use to retrive te whole context of the extractions (e.g. including the context identifier "383416952", one can use to serach the corresponding context in the resource described in the next paragraph).
- Contexts CSV files:
The above archive contains a set of tar file. Each tar file contains a set of "csv" file with the following format:link description contextsdb.tar.gz all the contexts of the extracted tuples
the first line of the csv files contains a comma separated list of the fields name i.e "_id,provid,sentence,pld".
The following lines of the files respect the schema of the head line e.g.:
"93459608,383416952,"This application has this option included too. Movie and TV series feature such characters as Aang, Prince Zuko, Katara, Sokka, Uncle Iroh, Commander Zhao, Fire Lord Ozai, Princess Yue, Katara's Grandma, Master Pakku, Monk Gyatso, Azula, Old Man in Temple, Zhao's Assistant, Earthbending Father.",appszoom.com"
where:- "93459608": the record identifier of the context as in the mongodb instance;
- "383416952": the context id that may be included in the "provids" filed of a tuple;
- "This application has this option included too. Movie and TV series feature such characters as Aang, Prince Zuko, Katara, Sokka, Uncle Iroh, Commander Zhao, Fire Lord Ozai, Princess Yue, Katara's Grandma, Master Pakku, Monk Gyatso, Azula, Old Man in Temple, Zhao's Assistant, Earthbending Father.": the sentence of the context;
- "appszoom.com": the pay-level domain.;
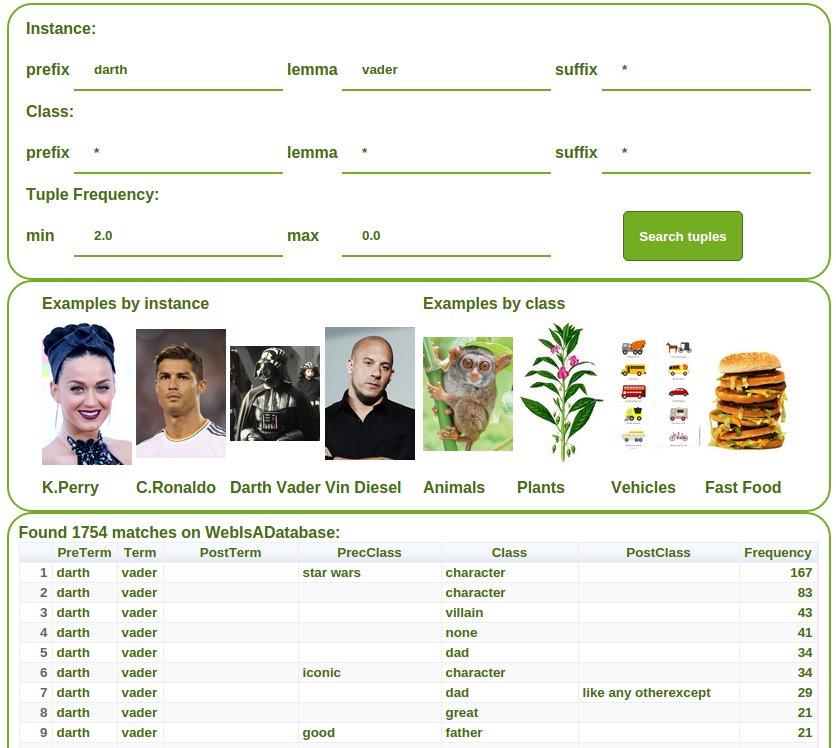
Figure 1: A screenshot of the Web application.
the first line of the csv files contains a comma separated list of the fields name i.e "_id,instance,class,frequency,pidspread,pldspread,modifications".
The following lines of the files respect the schema of the head line e.g.:
"286980418,aang,character,41,11,32,modification"
where:
Java API
The following archive contains the Java API to programmatically query the MongoDB instances of the WebIsADb:
WebIsADb-Java_API-src-maven_project-april-2016.tar.gz
The above package includes: a "readme.txt" with the instruction to configure the API and the "apidocs". Examples are also included in the main method of the file: "src/de/unima/webtuples/WebIsADb.java"
Relations extractor
The following archive contains the Java source code of the classes under the namespace "org.webdatacoomons.isadb":
webdatacommons_webisadb-tuple_extractor-src-april_2016.tar.gz
The above package requires the CommonCrawl framework and can be used to re-build a new WebIsADb from fresh CommonCrawl dumps.
4. Citing the WebIsA Database
Feel free to cite one or more of the following papers depending on what you are using.
- If you use the database:
Julian Seitner, Christian Bizer, Kai Eckert, Stefano Faralli, Robert Meusel, Heiko Paulheim and Simone Paolo Ponzetto, 2016. A Large Database of Hypernymy Relations Extracted from the Web. Proceedings of the 10th edition of the Language Resources and Evaluation Conference. Portorož, Slovenia; - If you use the web application:
Stefano Faralli, Christian Bizer, Kai Eckert, Robert Meusel and Simone Paolo Ponzetto. A Repository of Taxonomic Relations from the Web. Proceedings of the 15th International Semantic Web Conference (Posters & Demos) 2016.
The WebIsADb and the API are licensed under a Creative Commons Attribution-Non Commercial-Share Alike 3.0 License.
Acknowledgements
This work was partially funded by the Deutsche Forschungsgemeinschaft within the JOIN-T project (research grant PO 1900/1-1). Part of the computational resources used for this work were provide by an Amazon AWS in Education Grant award.